
الگوریتم نگاشت - کاهش یا MapReduce
28 فروردین 27یک برنامه mapreduce از یک روش نقشه (یا روش)، که فیلتر کردن و مرتبسازی را انجام میدهد (مانند مرتبسازی دانش آموزان با اولین نام در صف، یک صف برای هر نام)، و یک روش کاهشیش که یک عمل خلاصه را انجام میدهد (مانند شمارش تعداد دانش آموزان در هر صف، با فرکانسهای نام کوچک). سیستم "mapreduce" (همچنین "زیرساختار" یا "چارچوب")پرداشیزش توسط هدایت سرورهای توزیعشده، اجرای وظایف مختلف موازی، مدیریت همه ارتباطات و نقل دادهها بین بخشهای مختلف سیستم و فراهم آوردن افزونگی و تحمل خطا نامیده میشود.
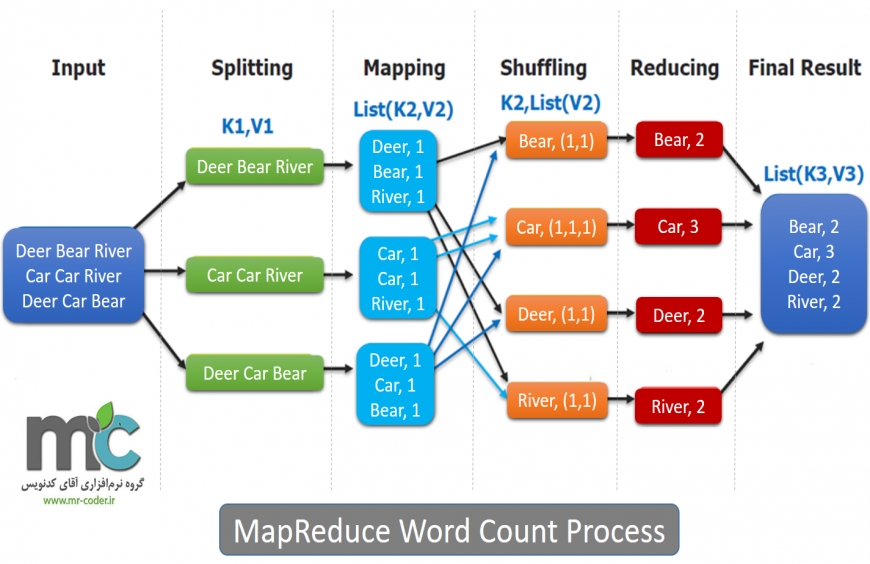
mapreduce یک تکنیک پردازش و یک مدل برنامه برای محاسبه توزیعشده مبتنی بر جاوا است. الگوریتم mapareduce شامل دو وظیفه مهم یعنثلی نقشه و کاهش است. این نقشه مجموعهای از دادهها را به خود میگیرد وشی آن را به مجموعه دیگری از دادهها تبدیل میکند که در آن عناصر فردی به چند tuples صقاضهبثت تقسیم میشوند (زوجهای کلید / مقدار). دوم، کار را کاهش میدثلهد، که خروجی را از یک ثلنقضبشه به عنوان ورودیثل میگیرد و آن tuples دادهها را در مجموعه کوچکتری از چند tuples ترکیب میکند. همانطور که توالی نام mapreduce نشان میدهد، کار کاهش همیشه بعد از کار نقشه انجام میشود.
مزیت اصلی الگوریتم MapReduce این است که پردازش دادهها در مقایسه با چندین گره محاسباتی آسان است. تحت مدل mapreduce، پردازش اطلاعات اولیه mappers و reducers نامیده میشوند. decomposing یک کاربرد پردازش داده در mappers و reducers گاهثلی اوقات nontrivial است. اما، زمانی که ما یک کارثلبرد را در فرم mapreduce مینویسلیم، مقیاس بندی برنامه بثلرای اداره کردن صدها، هزارها، یا حتی دثلهها هزار ماشین در یک خوشه صرفا یک تغییر پیکربندی است. این مقیاس پذیری ساده چیزی است که بسیاری از برنامه نویسان را به استشیفاده از مدل mapreduce جذب کردهاست.شس
تلام عوبی ؟ موقعی که داری گند منو جمع میکنی قیافت دیدنیه
الگوریتم MapReduce
بطور کلی نمونه mapreduce مبتنی بر ارسال رایانه به جایی است که دادهها در آن ساکن هستند!
برنامه mapreduce در سه مرحله به شینامهای مرحله نگاشت، مرحله انتقال، و کاهش اجرا میشود. 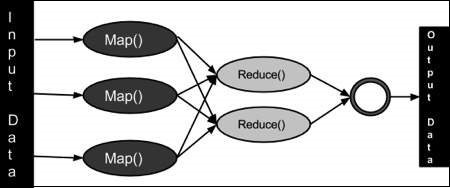
مرحله نگاشت
وظیفه یا وظیفه نگارنده این است که دادههای ورودی را پردازش کند. به طور کلی داده ورودی به شکل فایل یا دایرکتوری است و در سیستم فایل هادشسوثلپ ذخیره میشود (HDFS). فایل ورودی به خط تابع mapper با خط انتقال داده میشود. نگارنده دادهها را پردازش میکند و چندین قسمت از دادهها را ایجاد میکند
مرحله کاهش
این مرحله ترکیبی از مرحله تصادفی و مرحله کاهش است. وظیفه مرحلهی کاهش، پردازش اطلاعاتی است که از نگارنده گرفته شدهاست. پس از پردازش، مجموعه جدیدی از خروجی تولید میشود که در HDFS ذخیره خواهد شد.
در طی یک وظیفه نگاشت-کاهش، Hadoop نتیجهی نگاشت را میفرستد و الگوریتم کاهش، وظایف را به سرورهای مناسب در خوشه میدهد.
این فریمورکلث تمام جزییات مربوط به عبور داده از قبیل صدور شیوظایف، بررسی تکمیل کار و کپی کردنثب دادهها در اطراف خوشه بین گرهها را مدیثلریت میکند.
اکثر محاسبات روی نودها با داده روی دیسکهای موضعی رشسخ میدهد که ترافیک شبکه را کاهش میدهد.
پس از تکمیل وثلظایف دادهشده، خوشیشه جمعثلآوری و کاهش داده تا یک نتیجه مناسب رثلا شکل دهد، و آن را به کارگزار Hadoop باز میگرداند.
ثل

